Artificial information filtering#
In simple terms the bitinformation is retrieved by checking how variable a bit pattern is. However, this approach cannot distinguish between actual information content and artifical information content. By studying the distribution of the information content the user can often identify clear cut-offs of real information content and artificial information content.
The following example shows how such a separation of real information and artificial information can look like. To do so, artificial information is artificially added to an example dataset by applying linear quantization. Linear quantization is often applied to climate datasets (e.g. ERA5) and needs to be accounted for in order to retrieve meaningful bitinformation content. An algorithm that aims at detecting this artificial information itself is introduced.
To install all dependencies needed to run this example,
pip install "xbitinfo[example]"
is recommended.
import xarray as xr
import xbitinfo as xb
import numpy as np
Loading example dataset#
We use here the openly accessible CONUS dataset. The dataset is available at full precision.
Please note that s3fs needs to be installed to access this example dataset, e.g. via pip install s3fs
ds = xr.open_zarr(
"s3://hytest/conus404/conus404_monthly.zarr",
storage_options={
"anon": True,
"requester_pays": False,
"client_kwargs": {"endpoint_url": "https://usgs.osn.mghpcc.org"},
},
)
# selecting water vapor mixing ratio at 2 meters
data = ds["ACSWDNT"]
# select subset of data for demonstration purposes
chunk = data.isel(time=slice(0, 2), y=slice(0, 1015), x=slice(0, 1050))
chunk
<xarray.DataArray 'ACSWDNT' (time: 2, y: 1015, x: 1050)> Size: 9MB
dask.array<getitem, shape=(2, 1015, 1050), dtype=float32, chunksize=(2, 350, 350), chunktype=numpy.ndarray>
Coordinates:
* time (time) datetime64[ns] 16B 1979-10-31 1979-11-30
* y (y) float64 8kB -2.028e+06 -2.024e+06 ... 2.024e+06 2.028e+06
* x (x) float64 8kB -2.732e+06 -2.728e+06 ... 1.46e+06 1.464e+06
lat (y, x) float32 4MB dask.array<chunksize=(350, 350), meta=np.ndarray>
lon (y, x) float32 4MB dask.array<chunksize=(350, 350), meta=np.ndarray>
Attributes:
description: ACCUMULATED DOWNWELLING SHORTWAVE FLUX AT TOP
grid_mapping: crs
integration_length: month accumulation
long_name: Accumulated downwelling shortwave radiation flux at top
units: J m-2Creating dataset copy with artificial information#
Functions to encode and decode#
Artificial information filtering#
In simple terms the bitinformation is retrieved by checking how variable a bit pattern is. However, this approach cannot distinguish between actual information content and artifical information content. By studying the distribution of the information content the user can often identify clear cut-offs of real information content and artificial information content.
The following example shows how such a separation of real information and artificial information can look like. To do so, artificial information is artificially added to an example dataset by applying linear quantization. Linear quantization is often applied to climate datasets (e.g. ERA5) and needs to be accounted for in order to retrieve meaningful bitinformation content. An algorithm that aims at detecting this artificial information itself is introduced.
import xarray as xr
import xbitinfo as xb
import numpy as np
Loading example dataset#
We use here the openly accessible CONUS dataset. The dataset is available at full precision.
ds = xr.open_zarr(
"s3://hytest/conus404/conus404_monthly.zarr",
storage_options={
"anon": True,
"requester_pays": False,
"client_kwargs": {"endpoint_url": "https://usgs.osn.mghpcc.org"},
},
)
# selecting water vapor mixing ratio at 2 meters
data = ds["ACSWDNT"]
# select subset of data for demonstration purposes
chunk = data.isel(time=slice(0, 2), y=slice(0, 1015), x=slice(0, 1050))
chunk
<xarray.DataArray 'ACSWDNT' (time: 2, y: 1015, x: 1050)> Size: 9MB
dask.array<getitem, shape=(2, 1015, 1050), dtype=float32, chunksize=(2, 350, 350), chunktype=numpy.ndarray>
Coordinates:
* time (time) datetime64[ns] 16B 1979-10-31 1979-11-30
* y (y) float64 8kB -2.028e+06 -2.024e+06 ... 2.024e+06 2.028e+06
* x (x) float64 8kB -2.732e+06 -2.728e+06 ... 1.46e+06 1.464e+06
lat (y, x) float32 4MB dask.array<chunksize=(350, 350), meta=np.ndarray>
lon (y, x) float32 4MB dask.array<chunksize=(350, 350), meta=np.ndarray>
Attributes:
description: ACCUMULATED DOWNWELLING SHORTWAVE FLUX AT TOP
grid_mapping: crs
integration_length: month accumulation
long_name: Accumulated downwelling shortwave radiation flux at top
units: J m-2Creating dataset copy with artificial information#
Functions to encode and decode#
# Encoding function to compress data
def encode(chunk, scale, offset, dtype, astype):
enc = (chunk - offset) * scale
enc = np.around(enc)
enc = enc.astype(astype, copy=False)
return enc
# Decoding function to decompress data
def decode(enc, scale, offset, dtype, astype):
dec = (enc / scale) + offset
dec = dec.astype(dtype, copy=False)
return dec
Transform dataset to introduce artificial information#
xmin = np.min(chunk)
xmax = np.max(chunk)
scale = (2**16 - 1) / (xmax - xmin)
offset = xmin
enc = encode(chunk, scale, offset, "f4", "u2")
dec = decode(enc, scale, offset, "f4", "u2")
Comparison of bitinformation#
# original dataset without artificial information
orig_info = xb.get_bitinformation(
xr.Dataset({"w/o artif. info": chunk}),
dim="x",
implementation="python",
)
# dataset with artificial information
arti_info = xb.get_bitinformation(
xr.Dataset({"w artif. info": dec}),
dim="x",
implementation="python",
)
# plotting distribution of bitwise information content
info = xr.merge([orig_info, arti_info], join="outer")
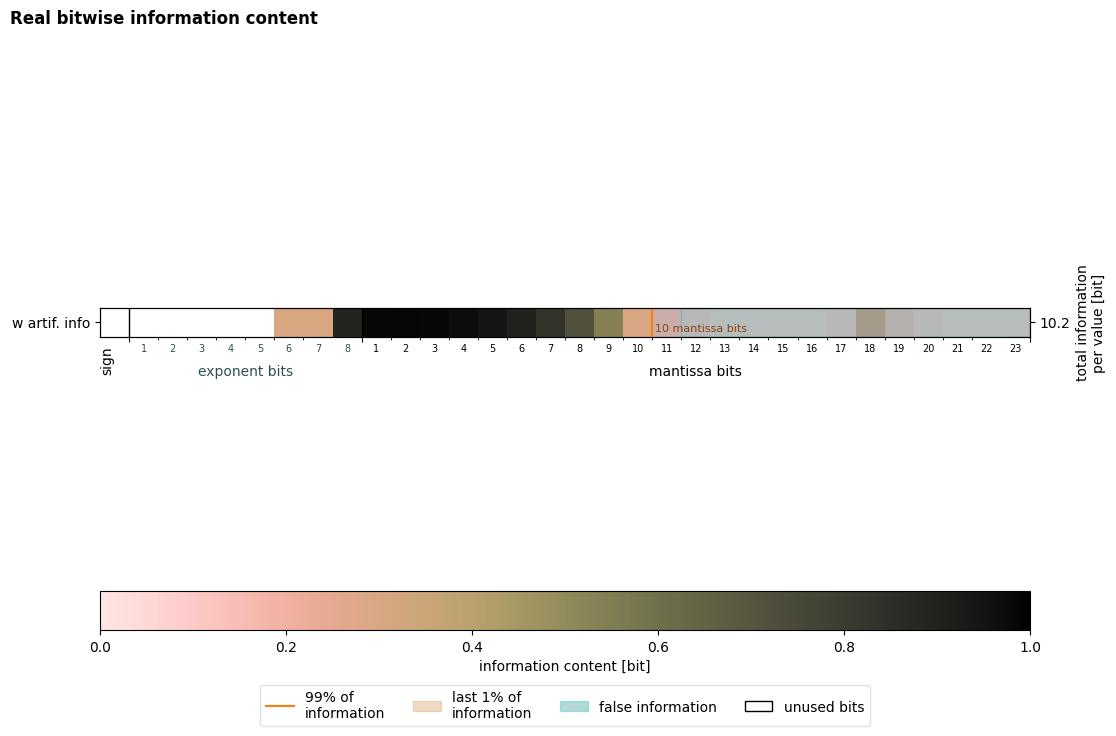
plot = xb.plot_bitinformation(info)
/tmp/ipykernel_2806/2482670718.py:16: FutureWarning: In a future version of xarray the default value for compat will change from compat='no_conflicts' to compat='override'. This is likely to lead to different results when combining overlapping variables with the same name. To opt in to new defaults and get rid of these warnings now use `set_options(use_new_combine_kwarg_defaults=True) or set compat explicitly.
info = xr.merge([orig_info, arti_info], join="outer")

The figure reveals that artificial information is introduced by applying linear quantization.
keepbits = xb.get_keepbits(info, inflevel=[0.99])
print(
f"The number of keepbits increased from {keepbits['w/o artif. info'].item(0)} bits in the original dataset to {keepbits['w artif. info'].item(0)} bits in the dataset with artificial information."
)
The number of keepbits increased from 10 bits in the original dataset to 18 bits in the dataset with artificial information.
In the following, a gradient based filter is introduced to remove this artificial information again so that even in case artificial information is present in a dataset the number of keepbits remains similar.
Artificial information filter#
The filter gradient works as follows:
It determines the Cumulative Distribution Function(CDF) of the bitwise information content
It computes the gradient of the CDF to identify points where the gradient becomes close to a given tolerance indicating a drop in information.
Simultaneously, it keeps track of the minimum cumulative sum of information content which is threshold here, which signifies at least this much fraction of total information needs to be passed.
So the bit where the intersection of the gradient reaching the tolerance and the cumulative sum exceeding the threshold is our TrueKeepbits. All bits beyond this index are assumed to contain artificial information and are set to zero in order to cut them off.
You can see the above concept implemented in the function get_cdf_without_artificial_information in xbitinfo.py
Please note that this filter relies on a clear separation between real and artificial information content and might not work in all cases.
xb.get_keepbits(
arti_info,
inflevel=[0.99],
information_filter="Gradient",
**{"threshold": 0.7, "tolerance": 0.001},
)
<xarray.Dataset> Size: 20B
Dimensions: (inflevel: 1)
Coordinates:
* inflevel (inflevel) float64 8B 0.99
dim <U1 4B 'x'
Data variables:
w artif. info (inflevel) int64 8B 10
Attributes:
xbitinfo_description: bitinformation calculated by xbitinfo.get_bit...
python_repository: https://github.com/observingClouds/xbitinfo
julia_repository: https://github.com/milankl/BitInformation.jl
reference_paper: http://www.nature.com/articles/s43588-021-001...
xbitinfo_version: 0.0.8.dev1+g16bc0d1
BitInformation.jl_version: 0.6.3With the application of the filter the keepbits are closer/identical to their original value in the dataset without artificial information. The plot of the bitinformation visualizes this:
plot = xb.plot_bitinformation(arti_info, information_filter="Gradient")